Redash导出仪表盘中所有数据为Excel文件
- 首发:2021-03-10 18:38:50
- 教程
- 7147
在《Redash刷新整个仪表盘API》一文中,提到了导出仪表盘中所有的Widget数据为Excel文件的需求。
实现该需求只需要调用官方的API,但是官方API文档对于使用的描述基本没有。
第一步:获取仪表盘数据,得到QueryID
通过请求
GET /api/dashboards/<dashboard_slug>?api_key=<API_KEY>
获取仪表盘数据。
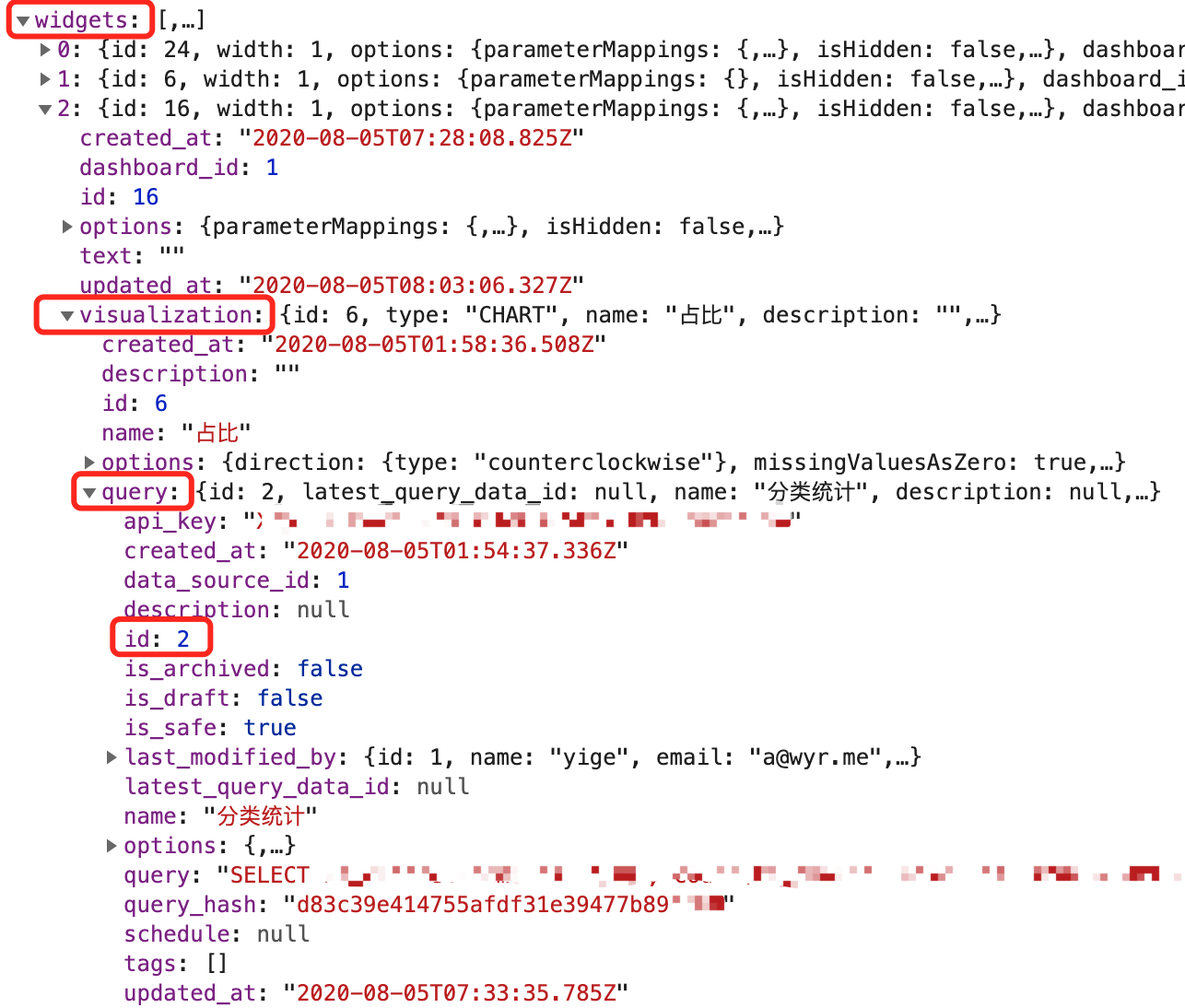
得到类似上图这样的数据。里面具有Widget所有信息。
第二步:通过 QueryIDs 启动查询
遍历widgets,拿到所有需要的item.visualization.query.id,然后挨个请求:
POST /api/queries/<item.visualization.query.id>/results?api_key=<API_KEY>
{
id: <item.visualization.query.id>,
parameters: {
created_at: {
start: <start> + ' 00:00:00',
end: <end> + ' 23:59:59'
}
}
}
这个请求的含义是“启动新的查询执行或返回缓存的结果”,此API将默认返回缓存的结果。如果没有缓存的结果,则新的执行作业开始,并返回作业对象。要绕过陈旧的缓存,请包含一个名为max_age值为整数秒的参数。如果缓存的结果早于max_age,则缓存将被忽略,并开始新的执行。如果设置max_age为0则始终开启新的执行,返回最新的执行结果。
这是一个异步设计的请求,需要对请求结果进行判断。如果返回的结果中含有job字段,说明启动了一个新的作业,否则将返回包含query_result的数据。
查询作业结果:
/api/jobs/<job_id>
- GET:返回查询任务结果(作业)
- 可能的状态:
- 1 ==待处理(等待执行)
- 2 ==已开始(正在执行)
- 3 ==成功
- 4 ==失败
- 5 ==已取消
- 状态为成功时,结果包括
query_result_id
- 可能的状态:
也可以不查询结果,不传入max_age: 0的情况下,重复调用接口,则作业完成后必然包含query_result数据。
第三步:拼接文件下载地址
拿到query_result后,拼接如下地址:
https://example.com/api/queries/<item.visualization.query.id>/results/<query_result.id>.xlsx?api_key=<API_KEY>
 此时将可以下载被自动命名的
此时将可以下载被自动命名的.xlsxExcel文件(跟后台手工下载的一样)。
修改拼接URL的文件名后缀,可以实现TSV、CSV、JSON文件的下载。
其它
整个过程涉及遍历接口、处理异步设计的接口、根据策略重新调用接口、多文件下载,对刚入门的同学来说是个不错的练手实例。
除特别注明外,本站所有文章均为原创。原创文章均已备案且受著作权保护,未经作者书面授权,请勿转载。
打赏
交流区
暂无内容




hi~
哈喽 轶哥大佬
win11 24H2 26100.2605 ,按照如下修改成功:
Search: 8B 81 38 06 00 00 39 81 3C 06 00 00 75 Replace: B8 00 01 00 00 89 81 38 06 00 00 90 EB
老师你好,我希望能用一个openwrt路由器实现IPv4和IPv6的桥接,请问我该如何实现?我尝试了直接新增dhcpv6的接口,但是效果不甚理想(无法成功获取公网的ipv6,但是直连上级路由的其他设备是可以获取公网的ipv6地)
你好
,为什么我这里是0039 813C 0600 0075 16xx xx xx,只有前6组是相同的,博客中要前8位相同,这个不同能不能照着修改呢?我系统版本是Win1124H2